Selenium 동적 데이터 실전 압축 크롤링
동적 데이터를 가져오기 위해 selenium을 써보자
Selenium으로 실제 데이터를 가져와보자
이전 글(정적 데이터 vs 동적 데이터)에서 크롤링에서 동적데이터와 정적데이터가 다른 것을 알아보았고 이제는 실제로 코드를 보면서 동적 데이터가 어떻게 다른지 알아보자.
Jobplanet 데이터를 가져와보자
실제로 쓴 코드를
import time
import os
os.system('pip install --upgrade selenium')
# 최신 버전 웹 드라이버 항상 불러오기
import selenium.webdriver as webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import sys
from selenium.webdriver import ActionChains
from datetime import datetime
driver = webdriver.Chrome()
url_start = 'https://www.jobplanet.co.kr/job'
major = '<원하는 주제>'
jobplanet_id ='<Your ID>'
jobplanet_pw = '<Your PW>'
driver.get(url_start)
time.sleep(2)
# 배너 무력화
driver.get(url_start)
# 로그인 클릭
#driver.find_element(By.XPATH, '//*[@id="JobPostingApp"]/div[3]/div[2]/div/div/div[2]/button').click()
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/header/div[2]/div[2]/a[1]/span').click()
# id pw 입력
driver.find_element(By.ID, 'user_email').send_keys(jobplanet_id)
driver.find_element(By.ID, 'user_password').send_keys(jobplanet_pw)
driver.find_element(By.XPATH, '//button[@class="btn_sign_up"]').click()
# 응답 기다리기
driver.implicitly_wait(100)
time.sleep(0.8)
# 카테고리 입력
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div/div/div/div[2]/div[1]/form/div/label/input').send_keys(major)
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div/div/div/div[2]/div[1]/form/div/label/input').send_keys(Keys.RETURN)
driver.implicitly_wait(100)
time.sleep(0.8)
# 액션체인으로 조작할 버튼이 있는경우 ()
# driver.find_element('//*[@id="job_search_app"]/div/div[2]/div[1]/div[1]/span[2]/span/select').click()
# driver.find_element('//*[@id="job_search_app"]/div/div[2]/div[1]/div[1]/span[2]/span/select/option[3]').click()
# driver.find_element('//*[@id="job_search_app"]/div/div[1]/div[2]/div/div[3]/div[1]/button[1]').click()
action_chains = ActionChains(driver)
# action_chains.drag_and_drop(driver.find_element('//*[@id="yoe_range_slider_container"]/span[2]'),driver.find_element('//*[@id="yoe_range_slider_container"]/span[1]')).perform()
# driver.find_element('//*[@id="job_search_app"]/div/div[1]/div[2]/div/div[3]/div[2]/div/div[2]/button[2]').click()
element = driver.find_element(By.XPATH,'html/body/div[1]/div[3]/div/div[1]/div[2]/div[2]/div/div[1]/div/div/div[1]/a')
element.click()
driver.implicitly_wait(100)
time.sleep(0.8)
driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[1]/div[1]/div/form/div/div/div/div/div/div/input').send_keys(major)
driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[1]/div[1]/div/form/div/div/div/div/div/div/input').send_keys(Keys.RETURN)
driver.implicitly_wait(100)
time.sleep(0.8)
def fmake_file(major):
output_file_name = 'jobplanet_'+major+str(datetime.today()).split(' ')[0]+'.txt'
output_file = open(output_file_name,'w',encoding='utf-8')
output_file.write("{}\t{}\t{}\t{}\t{}\n".format('분류','기업','직종','D-day','URL'))
output_file.close()
return output_file_name
def fcrawl_job(driver,i,output_file_name):
bodies = driver.find_elements(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[1]/div[2]/ul/li')
print(len(bodies))
j=len(bodies)
for k in range(1,j+1):
scroll = driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[1]/div[2]')
try:
if (k == 7):
driver.execute_script("arguments[0].scrollBy(0, 600)", scroll)
driver.find_element(By.XPATH, '//*[@id="job_search_app"]/div/div[2]/section/div[1]/div[2]/ul/li[' + str(k) + ']').click()
time.sleep(1.8)
driver.implicitly_wait(100)
job_title = driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[2]/div/div/div/div[2]/div/div/div[1]/h1').text
except:
job_title=' '
try:
job_enter = driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[2]/div/div/div/div[2]/div/div/div[1]/div/div/div/span[1]/a').text
except:
job_enter=' '
try:
job_url = driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[2]/div/div/div/div[2]/div/div/div[1]/div/div/div/span[1]/a').get_attribute('href')
except:
job_url=' '
try:
job_dday = driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[2]/div/div/div/div[3]/div/div[3]/div/div/div[1]/section/div[1]/dl/dd[1]/span[1]').text
except:
job_dday=' '
fwrite_job(major,job_enter,job_title,job_dday,job_url,output_file_name)
driver.implicitly_wait(100)
if i == 1:
globals()['max_page'] = driver.find_element(By.XPATH, '/html/body/div[1]/div[3]/div/div[2]/section/div[1]/div[2]/div/button[4]').text
if i == int(globals()['max_page']):
return
if i >=5:
i=5
i += 1
driver.execute_script("arguments[0].scrollBy(0, 600)", scroll)
next_page = driver.find_element(By.XPATH, '//*[@id="job_search_app"]/div/div[2]/section/div[1]/div[2]/div/button['+str(i)+']')
next_page.click()
return
def fwrite_job(major,job_enter,job_title,job_url,job_dday,output_file_name):
print([major,job_enter,job_title,job_url,job_dday])
output_file = open(output_file_name,'a',encoding='utf-8')
output_file.write("{}\t{}\t{}\t{}\t{}\n".format(major,job_enter,job_title,job_dday,job_url))
output_file.close()
return
def fmain():
output_file_name = fmake_file(major)
for i in range(1,31):
print('page'+str(i))
time.sleep(0.1)
fcrawl_job(driver,i,output_file_name)
driver.close()
fmain()
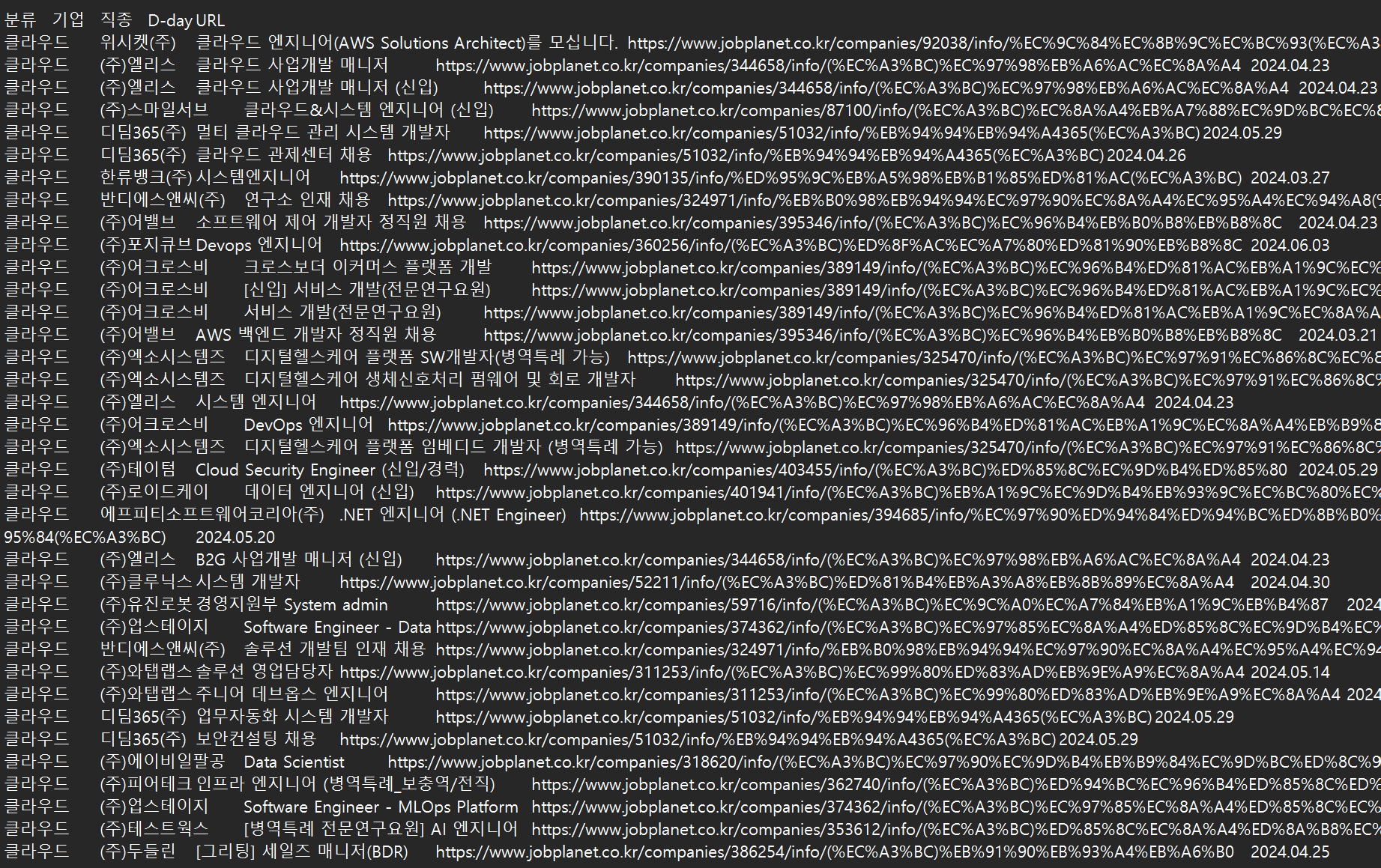
이런 식으로 데이터를 강제로 가져올 수 있다. 셀레니움 동작 중에는 스크롤을 넣거나 time.sleep 또는 implicity wait을 잘 응용해야 하는 경우의 수가 있는데 이는 직접 활용하다보면 익힐 수 있다. 주석에 대충 적어놨지만 주석이 없는 부분들도 찬찬히 직접 하다보면 알 수 있습니다.
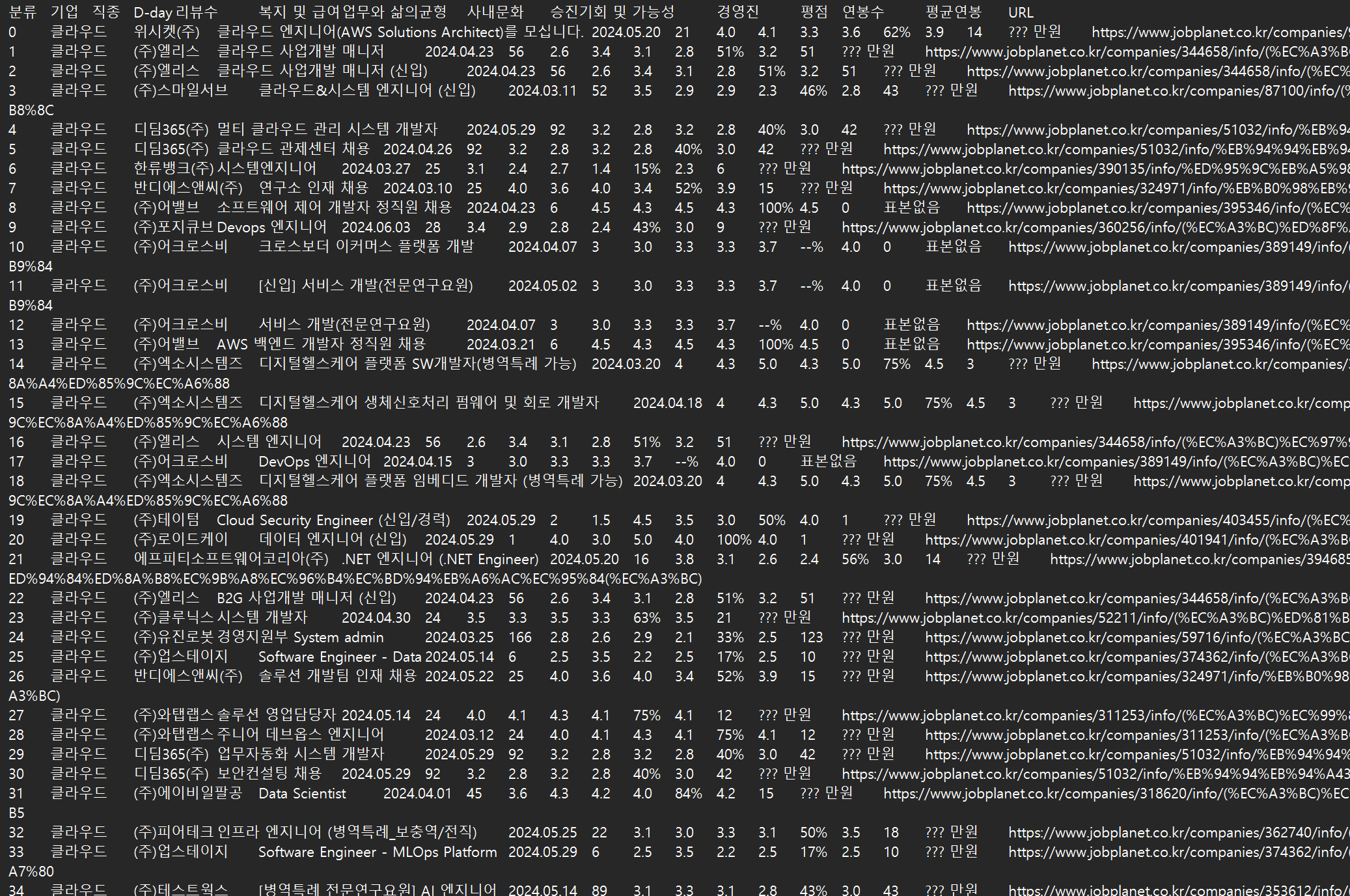
2차 크롤링을 통해 데이터를 이런식으로 기업별 점수까지 데이터를 가져올 수 있었다. 이를 csv로 가공하여 데이터 분석 또는 웹 등에서 활용할 데이터로서 활용할 수도 있습니다.
모든 코드는 공개하지 않지만 특정 데이터를 놓치지 않고 어떻게 포맷을 맞춰서 크롤링할 수 있는지 예시 코드와 함께 알아보았습니다. 자동화를 통해 앞으로 원하는 동적 데이터를 가져오는 경험을 통해 사용할 수 있는 데이터의 유형을 다양화할 수 있습니다. 다음에는 이러한 데이터를 통해 제가 직접 짭플래닛 즉 잡플래닛 데이터를 이용한 정적 웹 호스팅 사이트를 구현해보는 것도 보여드릴 수 있을 것같습니다.
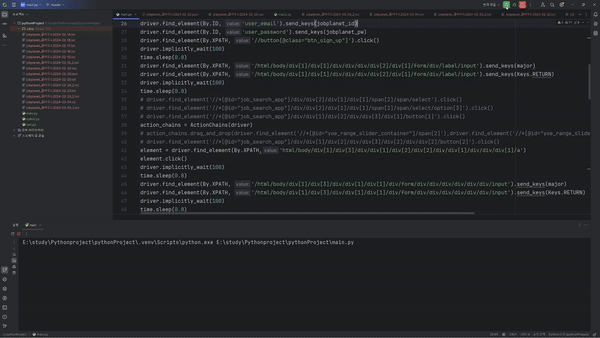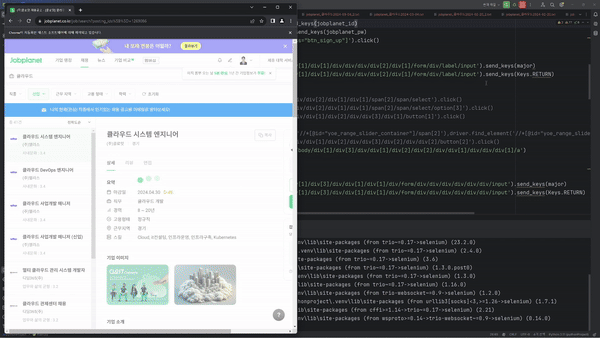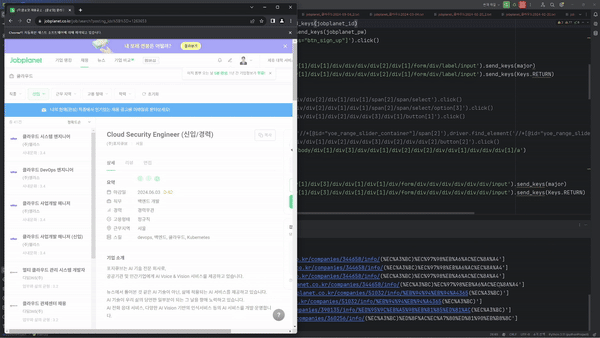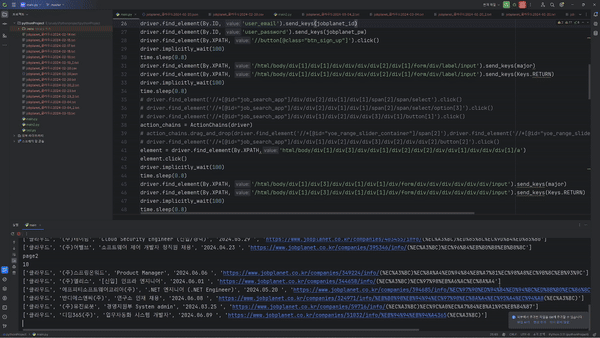
마지막으로 이런식으로 크롬 웹브라우저가 자동적으로 움직이는 것을 볼 수 있습니다.