동적 데이터 vs 정적 데이터
동적 데이터의 개념과 가져오는 방법
정적 데이터 vs 동적 데이터
늦었지만 이전 글(크롤링 완전 정복)에서 크롤링에서 셀레니움을 사용해야 하는 상황에 대해 얘기한 적이 있다. 일반적으로 크롤링을 할때는 먼저 가능하다면 beautifulsoup를 활용해 html파일을 직접 가져오는것이 경제적이고 빠르다.
그렇다면 경제적이지도 빠르지도 않은 셀레니움 웹드라이버를 활용한 크롤링은 언제 필요하고 왜 해야 하는지 알아보자
정적데이터, 동적데이터란?
웹 서버는 client에게 html을 보내준다. 웹 브라우저는 이러한 client의 html을 전송받아 화면에 띄워준다. 문제는 프론트 서버가 점점 api를 통해 사용자의 데이터 혹은 사용자의 입력을 받아야 javascript등을 통해 적절한 데이터를 제공하는 형태로 변하고 있는 것이다. 반대로 정적데이터는 우리가 별다른 동적인 움직임을 보이지 않더라도 html에 고정적인 static 한 데이터를 html을 통해 정확하게 보여준다. 예시를 들기 위해 크롬개발자 도구에서 Disalbe Javascript 버튼을 활성해 자바 스크립트를 비활성 후 wiki 백과의 한 페이지를 들어가보겠다.
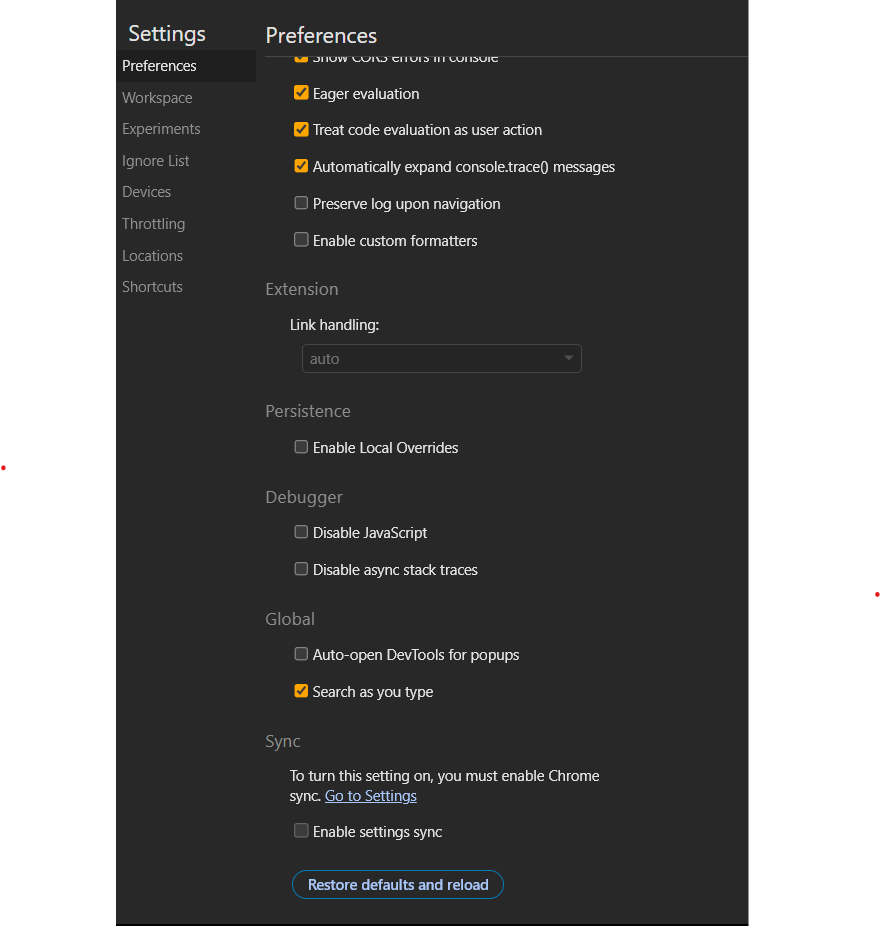
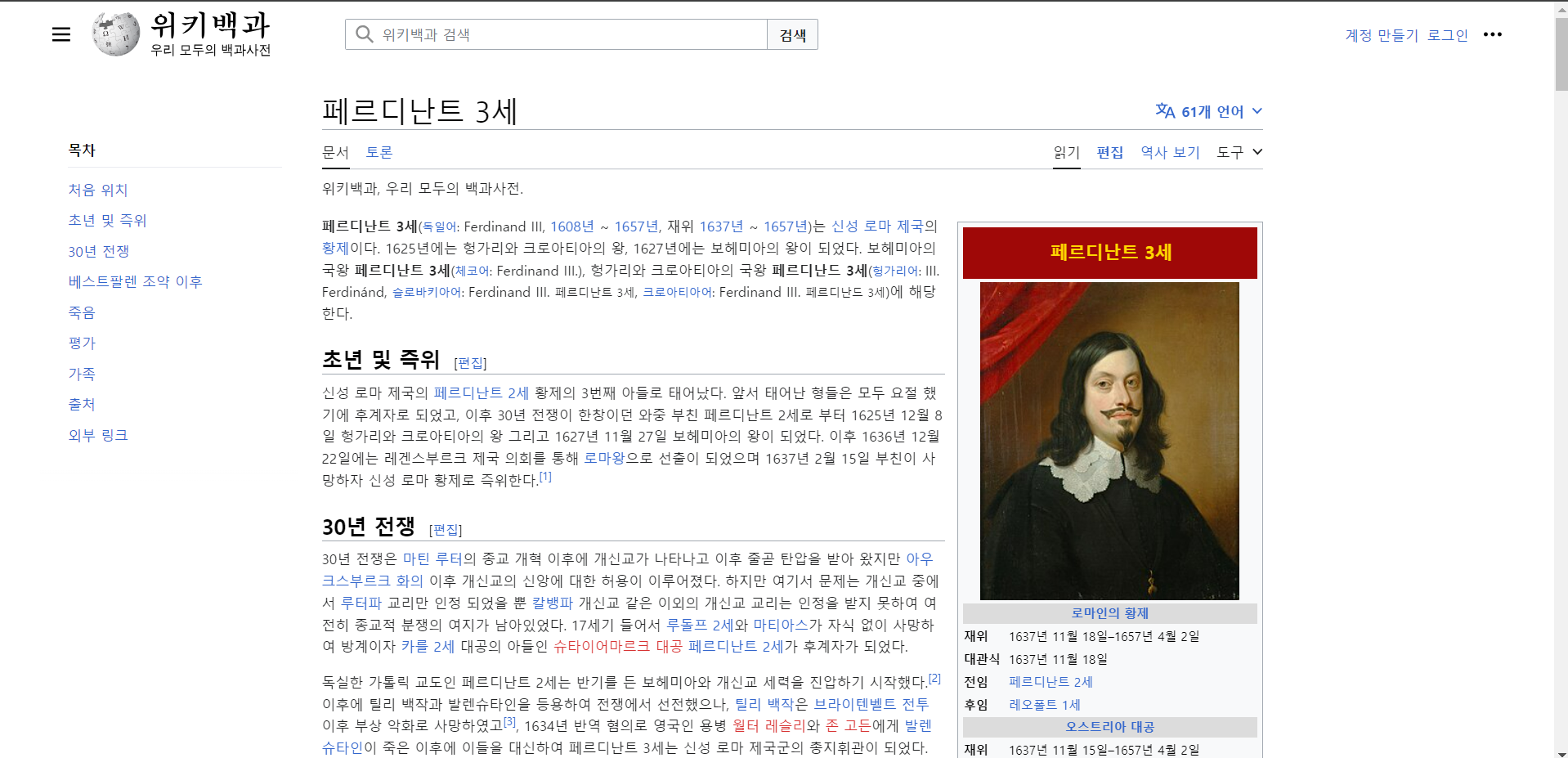
우리는 깔끔하게 위키 백과의 모든 내용 이미지 등을 확인할 수 있다. 심지어 광고조차 뜨지 않는 것을 볼 수 있다. 이렇게 wiki 백과사전은 정적인 데이터를 사용자에게 제공해주는 것을 확인해 볼 수 있다. 만약 이러한 페이지의 정보를 크롤링한다면 매우 경제적이고 빠르게 크롤링이 가능하다.
그럼 반대의 경우 동적 데이터를 알아보자 youtube에서 JavaScript를 비활성시 우리는 아무런 동영상 정보를 확인할 수 없다. 사용자의 데이터를 읽어 사용자에 맞춤 데이터를 제공하는 youtube는 동적데이터를 제공하는 것이다. 요즘은 사용자의 정보 또는 사용자의 입력을 받아 그에 맞춘 데이터를 제공하는 프론트서버가 매우 많다. 따라서 이러한 곳에서 데이터를 가져오고 싶다면 셀레니움의 웹 드라이버를 활용해야 하는 것이다.
즉 요약하자면 가장 빠르게 내가 가져갈 데이터를 정하고 그것을 어떻게 크롤링 할지는 정적데이터와 동적데이터냐에 따라 계획과 코드가 달라지고 이것을 빠르게 판단하는 것은 크롬 개발자도구에서 자바스크립트를 비활성화 시키고 새로고침을 해보면 간단하게 알 수 있다. 그리고 다음에 셀레니움을 통한 자동화 크롤링을 예시를 보겠습니다.