Selenium을 통한 실전압축 크롤링
자동 크롤링을 통해 원하는 데이터를 얻자
크롤링을 통한 웹 자동화
크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위입니다.
기존에는 beatifulsoup라는 모듈을 사용해도 충분했지만 요즘 웹은 앱에 버금갈 정도의 동적이고 사용자중심의 경험을 제공하면서 그냥 html을 다 가져온다고 데이터를 추출할수가 없게 되었습니다.
예를 들어 html을 가져와도 js에 따라 클릭과 적절한 동작을 취해야만 ‘span’되는 정보들이 많아졌고 이를 가져올려면 웹을 컨트롤해야 되는 경우가 많아졌습니다.
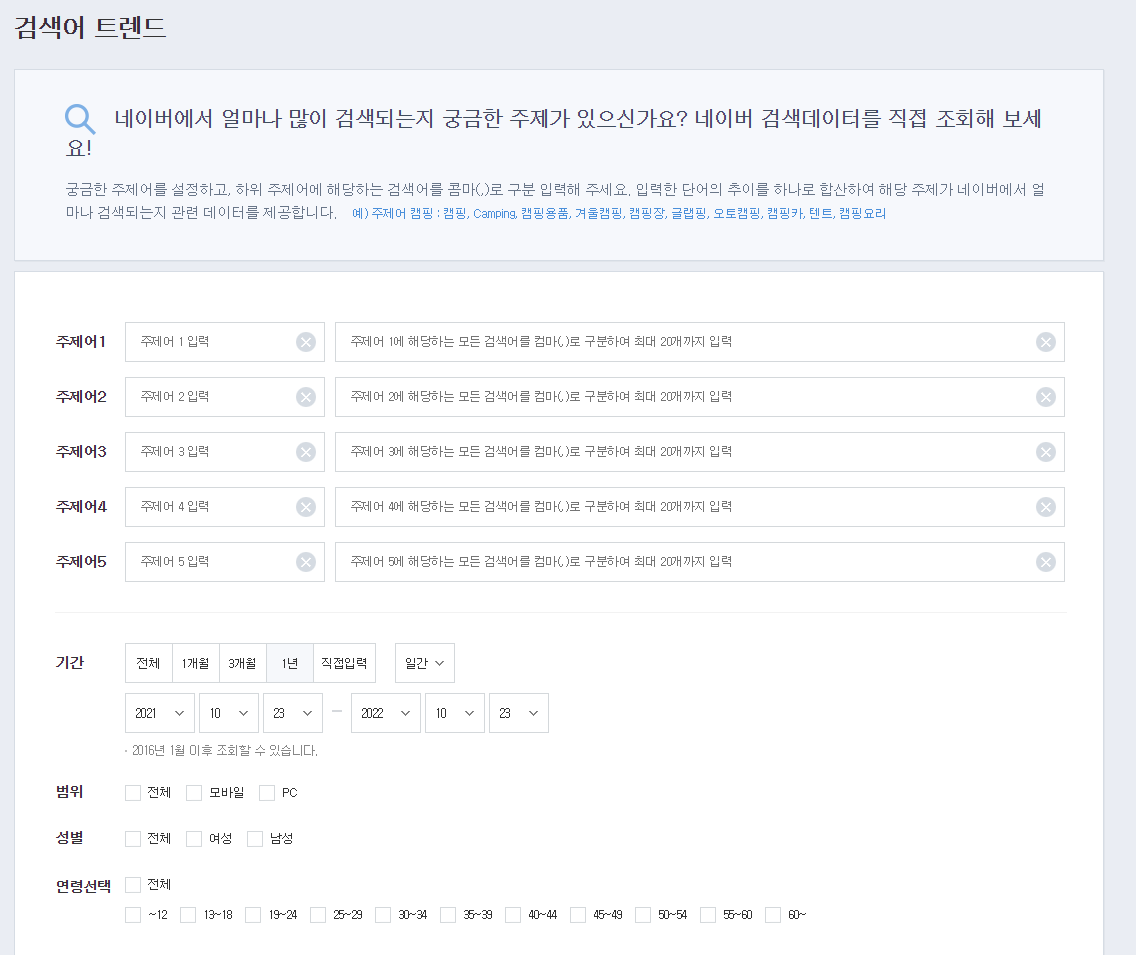
간단한 예로 네이버에서 실시간 검색어에 대한 정보를 보려면 다음 처럼 검색어를 미리 지정해서 해당 검색어에 대한 정보를 얻거나 대표적인 분류(쇼핑,디지털/가전) 이런식으로 분류를 완료해야 정보를 보여줍니다.
저는 물론 html에서 바로 데이터를 가져올 수 있으면 그거만큼 베스트가 없겠지만 대부분은 selenium을 활용 웹을 자동화 또는 조작하면서 거기서 데이터를 얻는 방식을 추천드립니다.
마지막으로 모든 crawling과 웹 자동화는 본인이 정말 필요하거나 하고 싶은걸로 하시는 것을 먼저 해보는 것을 추천드립니다.
저는 잡플래닛에서 데이터 직무에 대한 모든 자료를 긁어오는 것을 프로젝트로 설정하였습니다.
먼저 잡플래닛에서 가져올 수 있는 정보는 채용공고 해당 기업에 대한 정보 인데 여기서 해당 기업에 대한 정보는 해당 기업에 대한 리뷰와 각 평가항목별 점수 연봉들입니다. 그리고 주요한 점은 리뷰에 대한 정보를 위해서는 어느정도 아이디에 대한 권한이 필요합니다. 저는 제휴대학 이메일을 통해 해당 데이터에 접근할 수 있는 권한을 가졌습니다.
다음시간에는 특정 검색어에 대한 직업채용공고를 통한 해당 기업들의 정보를 알아보고 이를 통해 해당기업의 데이터를 시각화 하는 법을 대해 알아봅시다.